ULC Schedule Maker
The ULC Schedule Maker is a web app designed to streamline schedule creation at the University Learning Center at New York University.
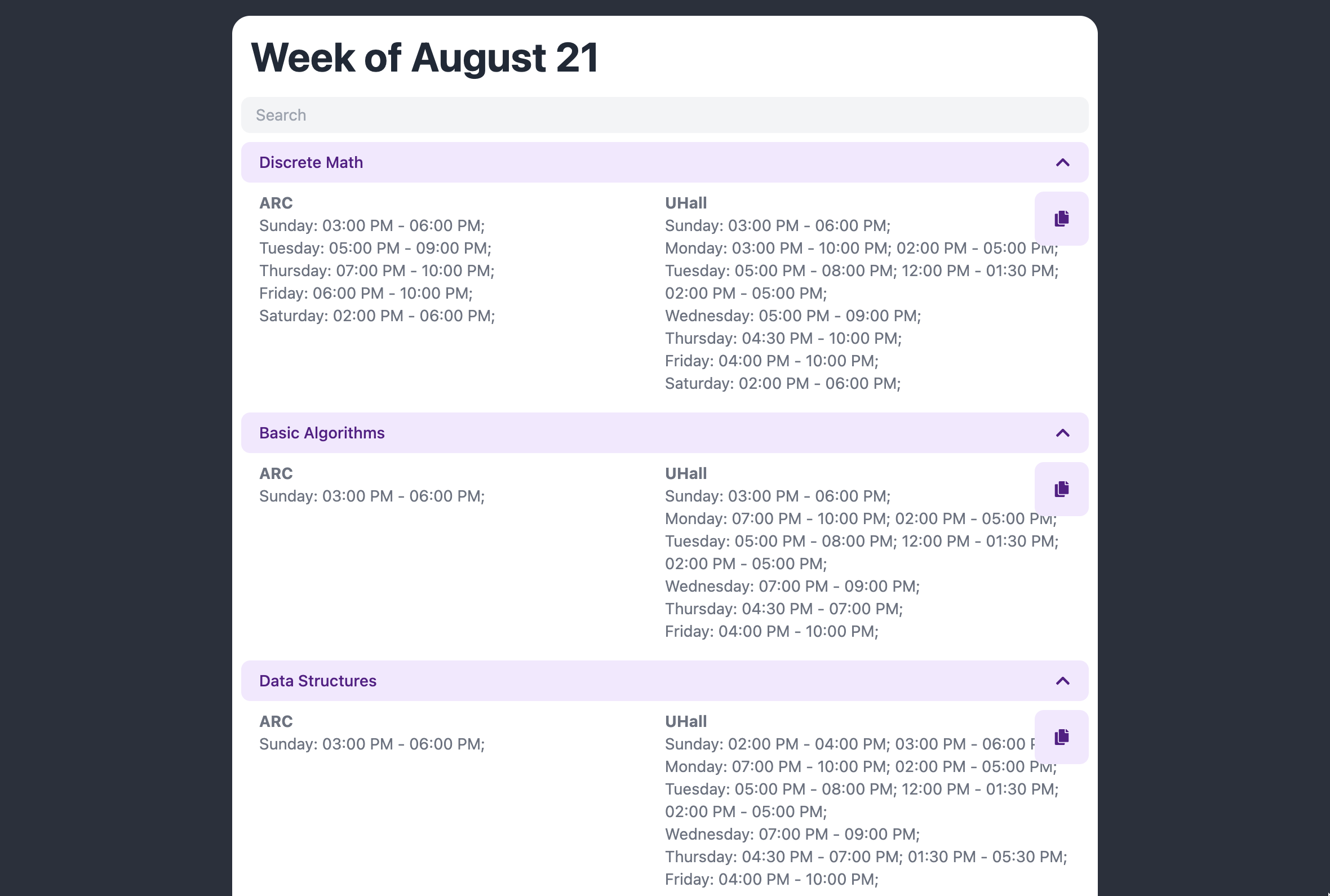
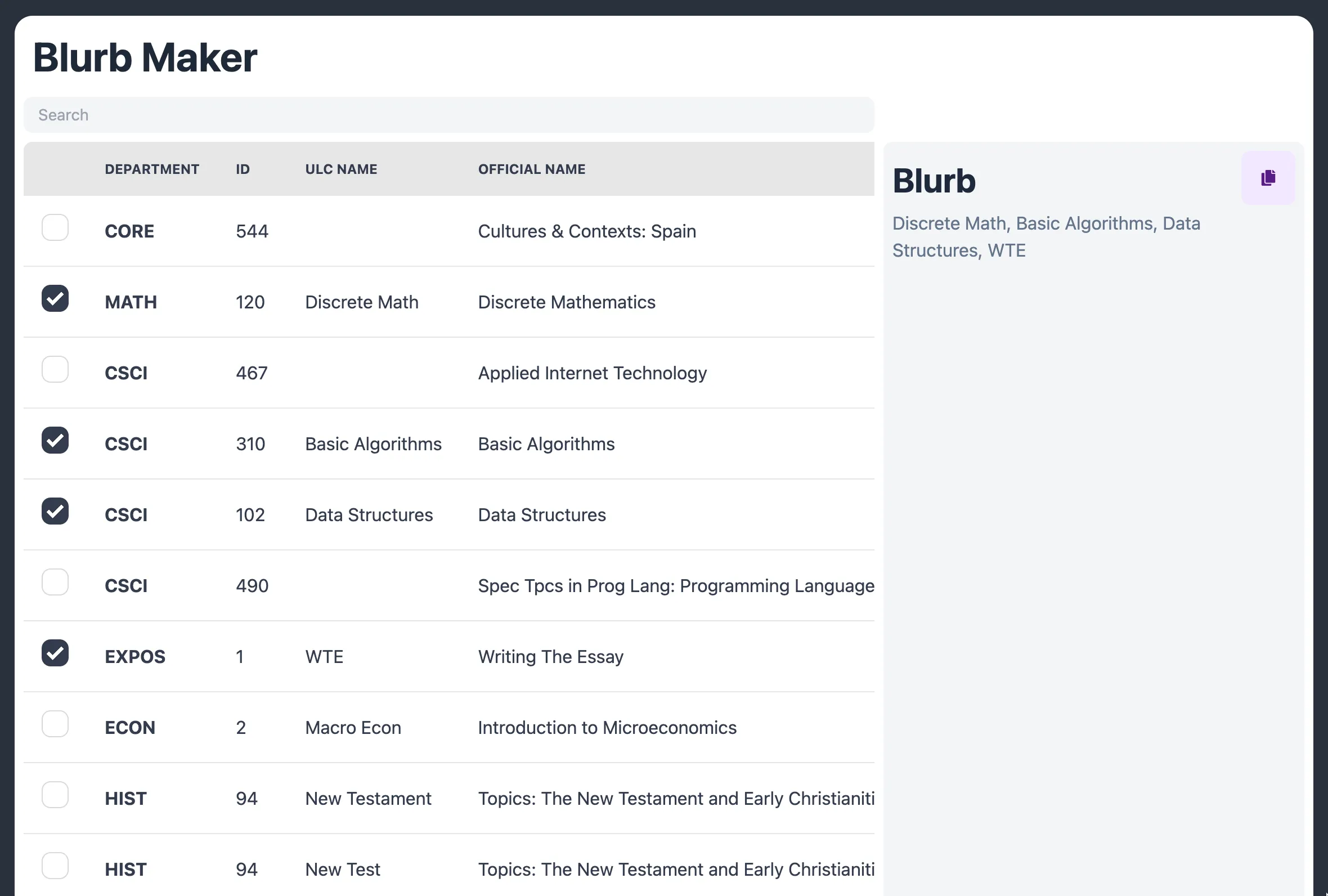
We set out to convert the chaotic Google Calendar schedule our director prepares to one that is easily digestible on the ULC website, aggregated by course, and then by day.
Next.js, React, Express, MongoDB
2022
3 months
TypeScript
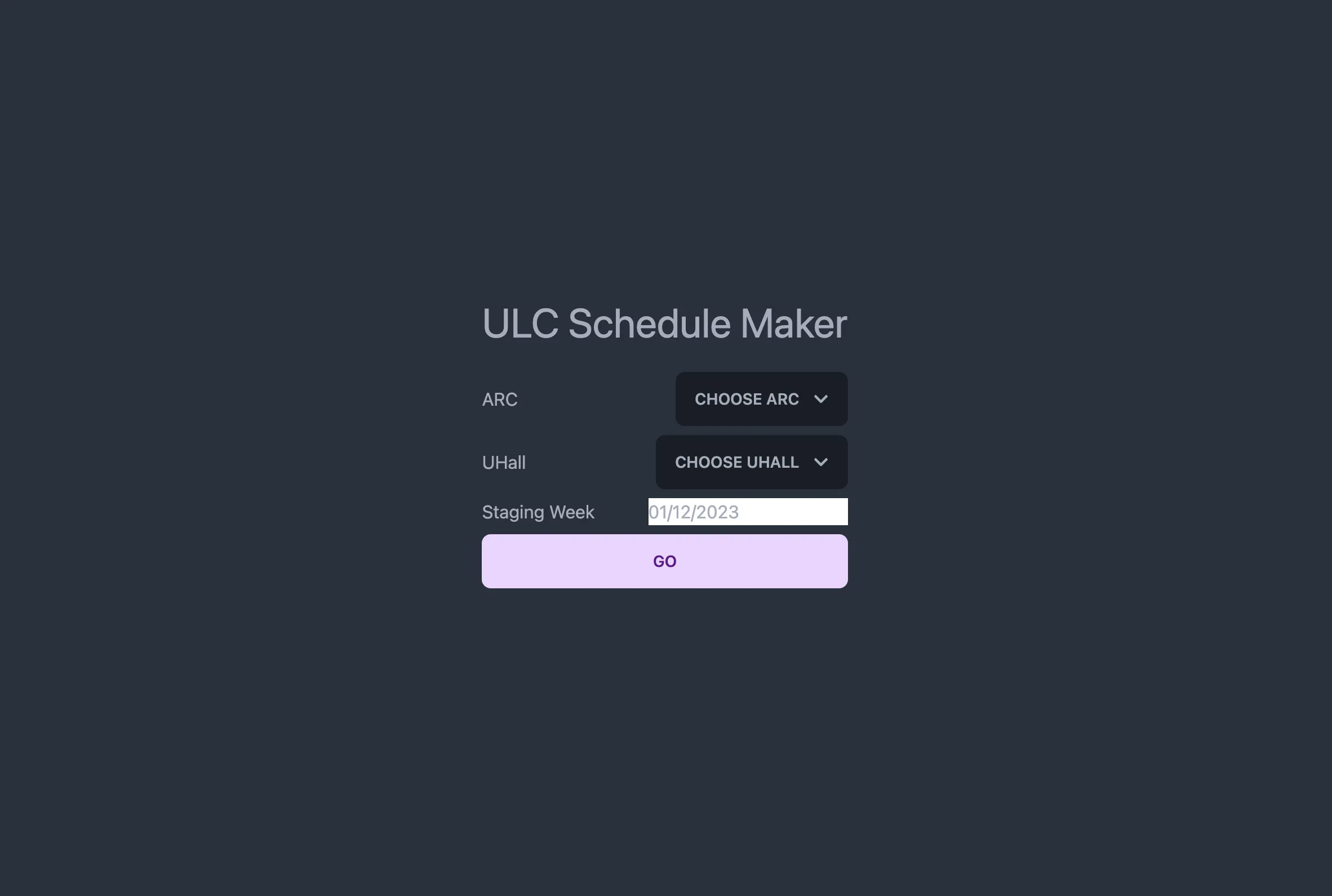
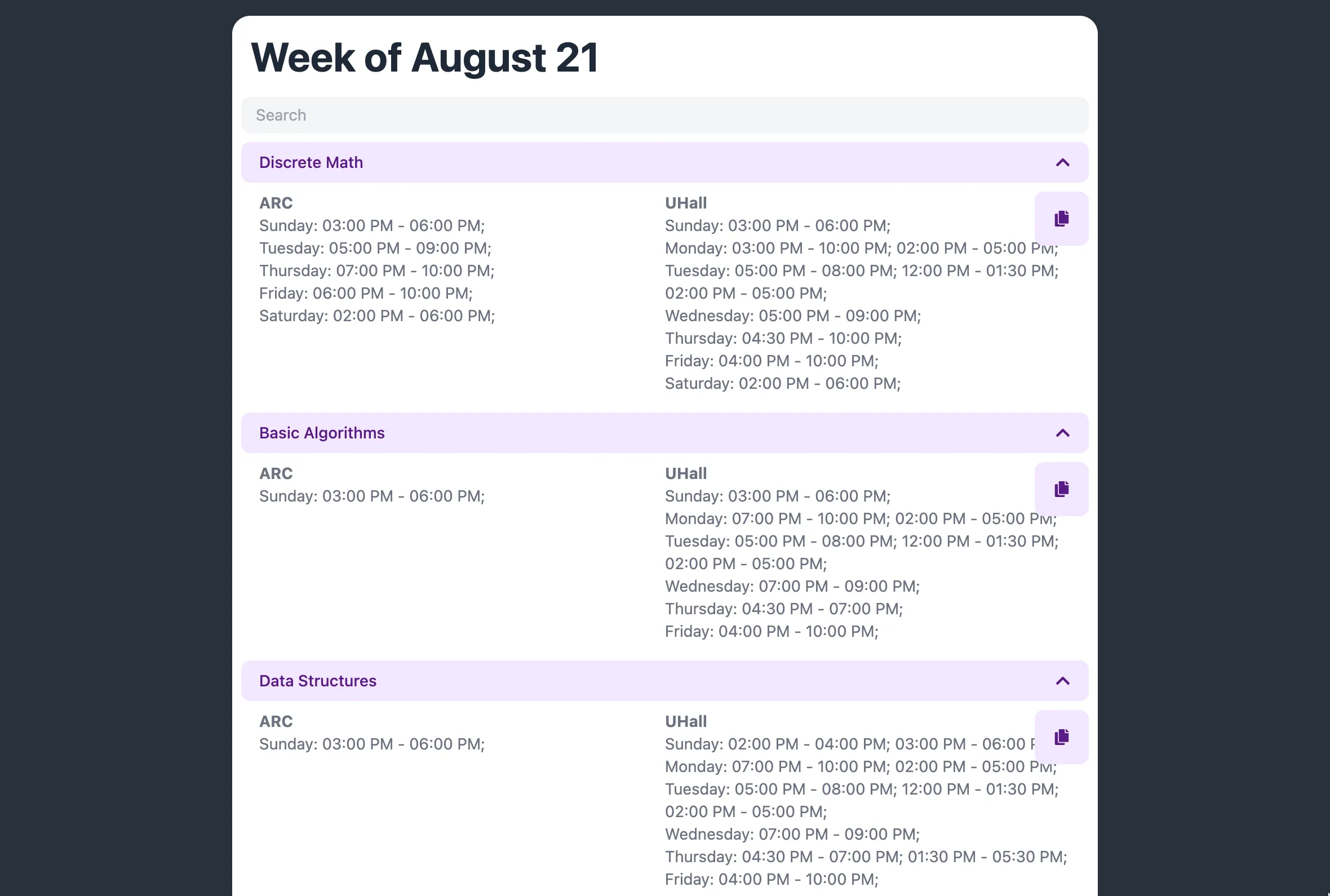
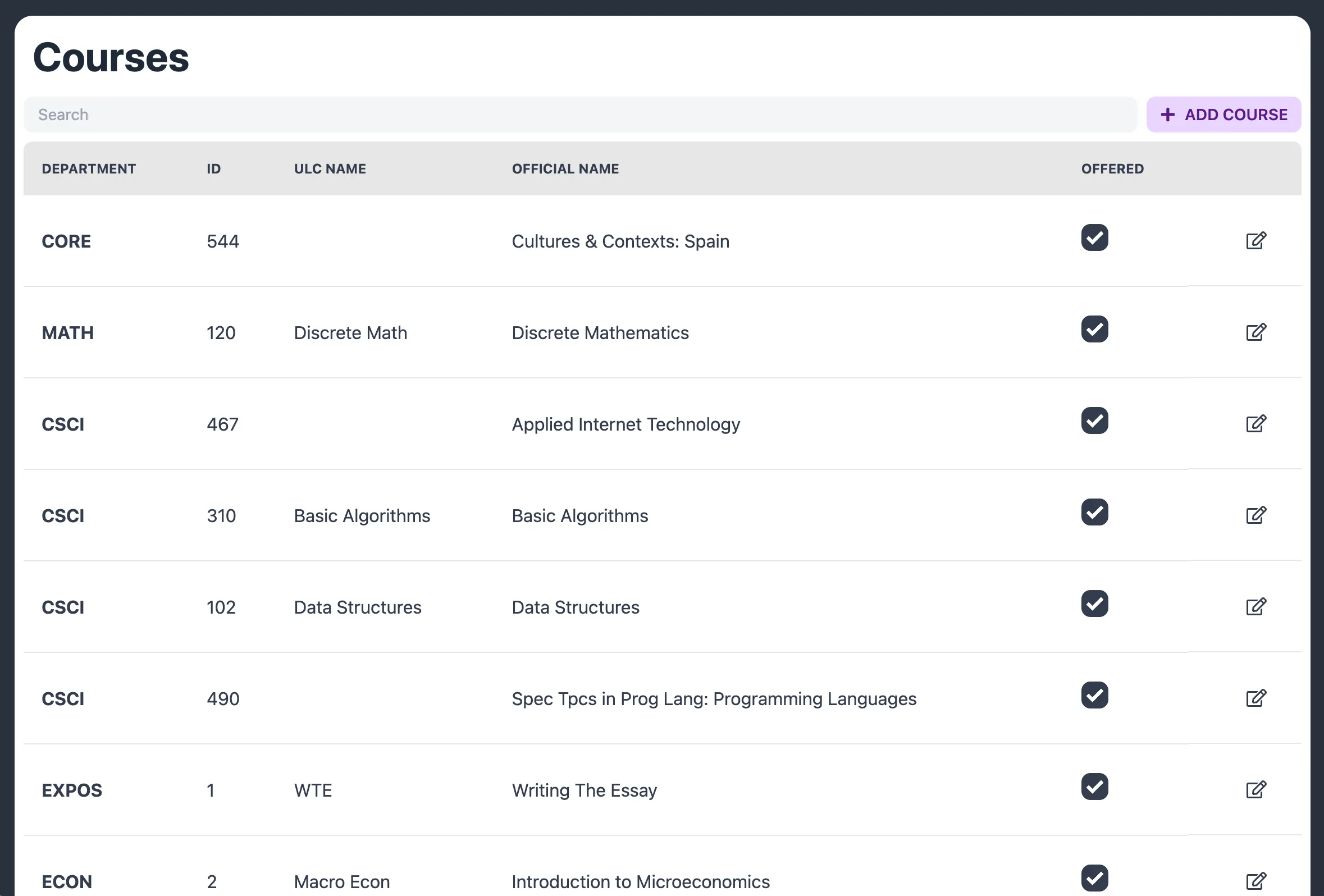
Background
I work at the University Learning Center, New York University’s free peer-tutoring organization. In my work as a Learning Assistant there, I end up seeing a lot of students, largely looking for help with Computer Science, Math, and Writing. However, that is far from all we do at the ULC. The ULC offers a multitude of courses, the extent of which can be seen on our website. To offer the variety we do, we have a staff of around 60 people (and growing!)1
Our directors have the unenviable task of making our schedules, from availability we send over, and then figuring out what times each class is available, to put on the website. This process is both slow, and error-prone. We noticed that, despite our best efforts, there were always issues with the schedule on the website.
That is where the idea of the schedule maker was born. We aimed to automate this process, and we decided to do it through making a web app.
Features
Unlike most university computer science projects, we knew we’d actually have users. We began by considering what our directors would actually want in this sort of tool. The main idea was to import the Google Calendar crafted by the directors, and spit out something that could go on the website, but there were complexities abound.
We thought about a few things initially, and added things along the way2:
-
Google Auth: We would require Google login through OAuth, so that we can fetch the calendar info. We’d also require auth on our end to make sure that only our directors could access functionality.
-
Binning Algorithm: The events we get from the calendar are centered around tutors, and their availability. Since our tutors teach a lot of different courses, we would need to change this focus, and bin according to course instead. To do this we needed to create an algorithm that would do these transformations for us, and merge overlapping events.
-
Support for multiple locations: The ULC operates in multiple locations across campus, so we needed to make sure that we were creating a product that spits out different schedules for the different locations.
-
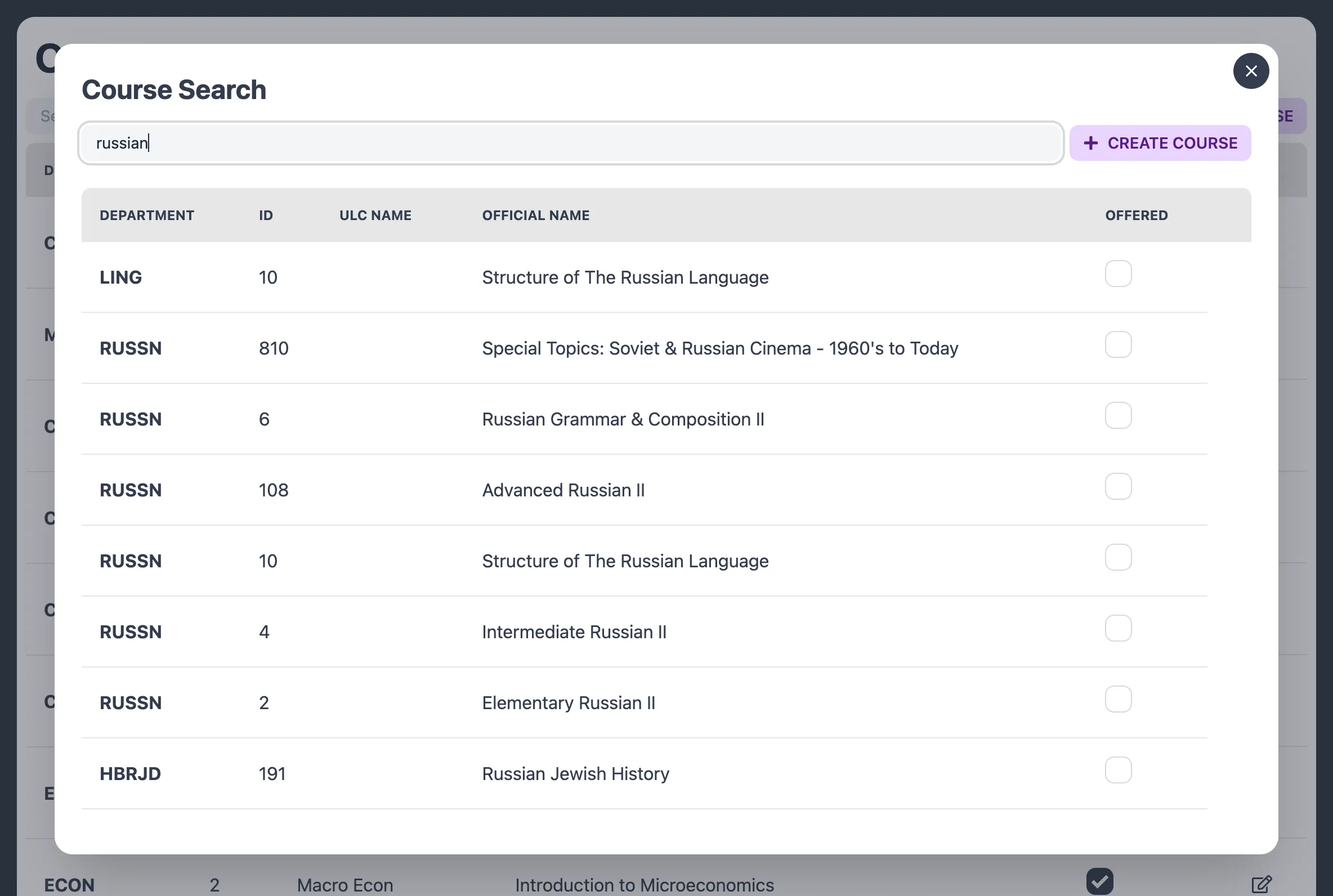
Source of truth: We needed some canonical list of courses the ULC would support, but required flexibility if someone wanted to tutor a course that wasn’t on that list.
-
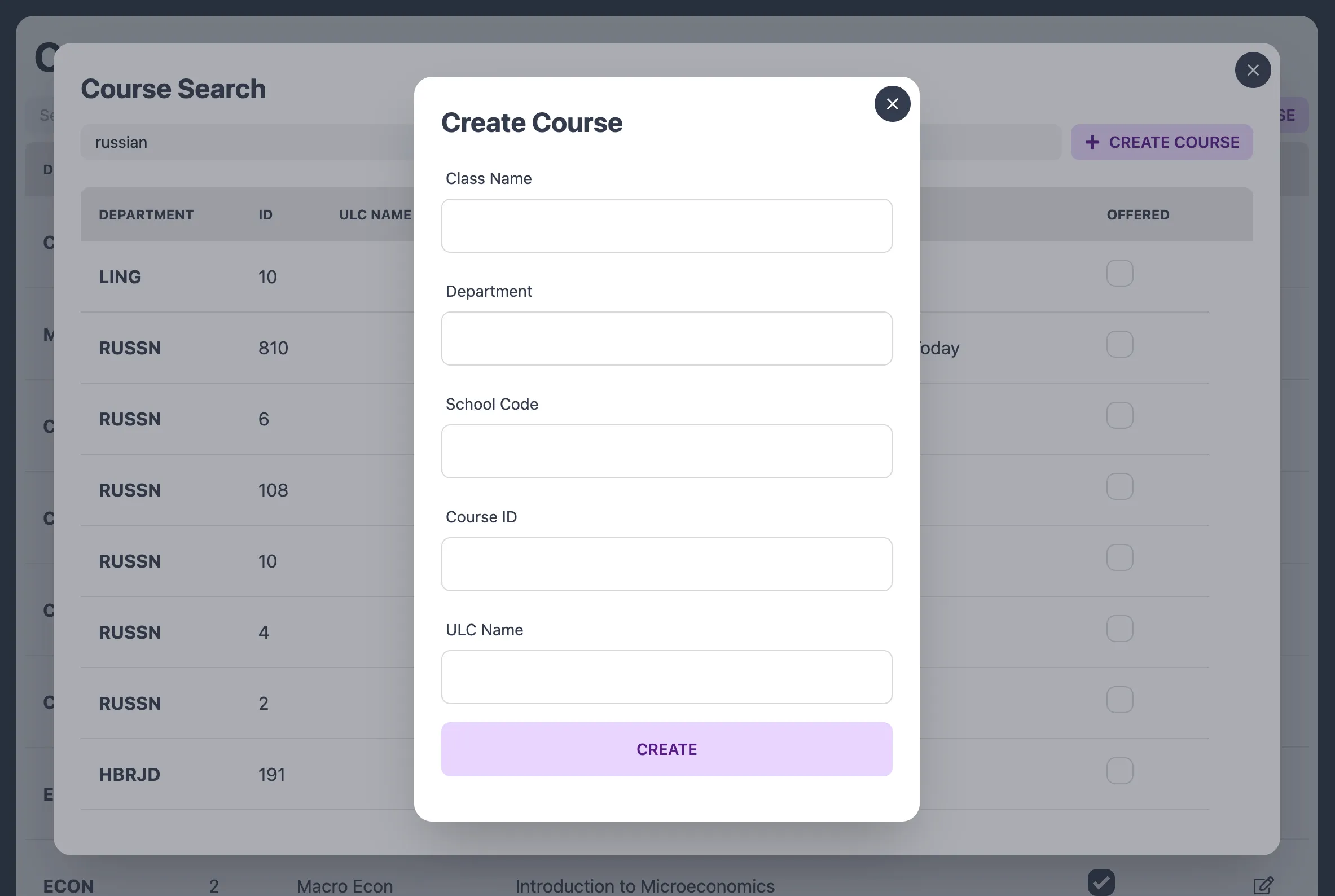
Class information import: One thing our directors really disliked doing was manually updating the aforementioned course list with the correct information: the course ID, canonical name, department, etc. We needed a way to minimize their frustration.
-
Good UX: The last thing we needed was for the users of our application to ask us how to use it. We wanted to make the product as intuitive as possible. This also meant having good documentation for our users, so that need to come to us less. Finally, this meant good error messaging. Errors are bound to happen with an app of this complexity, and bad errors are endlessly frustrating.
Stack Considerations
Beginning this project, we had a few considerations in mind. Our development team was small, just three CS tutors, and we’d have limited time to work on the project (we had to juggle schoolwork, work at the ULC, and now this). Therefore, we needed a stack we were all fairly comfortable with.
After much deliberation, we landed on the classic MERN (MongoDB, Express, React.js, Node) stack, with Next as our meta-framework for React. We considered using Django, for its integrated auth, database, and default admin pages. However, our onboarding time would be considerable, and we’d have to use Python, a language none of us are super into.
We were all into the idea of a strongly typed language, and the idea of sharing types across the backend and frontend was very compelling. That’s why we ended up standardizing on TypeScript for the whole project, using type-safe React, type-safe Express, and even type-safe database calls.
This idea, as it turns out, has been becoming more and more popular in the web dev space, and a lot of work is going into better tooling and developer experiences in the area. Had I known about some of these projects, like tRPC, and Next’s great API support, I think I would’ve pushed for us to use them; they look magical.
Implementation
Implementing the schedule maker took a lot longer than we had expected, especially as the scope of the project grew. We began by pair programming a lot. While fun and largely productive, we knew we’d need to parallelize to make the most of our limited time. Keeping both the frontend and backend in lock-step, however, was a challenge. Often one of us would be working on a feature without knowing how it would plug in to the rest of the project.
This isolated work pattern forced us to get creative. Here, we used TypeScript to our advantage. Every week, our first order of business was to figure out the types associated with the feature we were to build, along with any API routes, and the types of requests and responses associated with them. A concrete understanding of these types allowed us to split off and work separately without having to worry about whether it would fit together without breaking.
This led to us developing very rapidly, and also had the knock-on effect of being better documented than any of my previous projects. The type documentation and API documentation we ended up with is some of the best I’ve seen for a small project like this.
With that overall approach, we tackled the features we wanted to implement:
-
Google Auth: Because we were using express, we relied on passport for authentication, despite its admittedly lackluster documentation, which caused me many a headache. We stored auth info both on the session, and in our MongoDB database, which we were hosting on Atlas, their quick and easy way to get a database running on the cloud. It has been working great for us.
-
Binning Algorithm: The binning algorithm was reminiscent of classic scheduling algorithms taught in an algorithms course. Its design involved a lot of whiteboarding, and even more types. We had to deal with inconsistencies in the parsing of events from Google Calendar, leading to some very annoying edge cases (one especially infuriating one was the use of em dashes instead of en dashes, which messed with our parser.)
-
Support for multiple locations: This was largely a UI problem. Our UI had to be intuitive enough to support multiple locations, which was somewhat difficult to do, but was managed by relying on modern responsive CSS tech (largely flexboxes and grids.)
-
Source of truth & class information import: Prior to this project, the closest semblance we had to a source of truth was a half broken Google Sheet that contained some class information. It had been manually added to over years, and was very difficult to work with. Sanitizing that data would not have been fun.
Ideally, we would have liked to get course information straight from NYU. However, after trying and failing multiple times to get access to NYU’s class API, we gave up on the idea. Instead, we used Schedge, a really nice API created by an NYU alum, with information he scraped from the NYU course search site.
This ended up also solving the class information import problem: we now had access to every single course taught at NYU, which we had put into our database, from the Schedge API.
-
Good UX: This was very much a process. None of us are designers, and we were somewhat out of our depth. However, we ended up with something that I believe is perfectly usable, and even looks pretty nice (thanks to Tailwind, which I absolutely adore.)
Results
We ended up with a product that I am fairly proud of. It solves a specific problem that we faced, and sped up the creation of the schedule for the website, freeing time for our directors to work on things that are more important. Screenshots from the project, and descriptions of them, follow.
This project was completed by Laksh Chakraborty, Bruce Wu, and Amani Hernandez, with mentorship from EJ Kim.
Footnotes
-
The return from COVID has been massive for us, and our staff has ballooned; the ULC has never been more busy. Turns out students didn’t quite like online pedagogy. Who knew! ↩
-
Yay, scope creep! We did try to keep this to a minimum (I’ve been bitten by scope creep too many times to count), but some still made its way in. ↩